You might be surprised but it is not that simple. Some cases of strange results CAN mean that the coin is biased. There is quite a bit of science about the whole so-called “fair coin problem”.
Isn’t the whole point here though that while it might be statistically possible to get these long streaks, they are annoying players and not good for the game either way - so code some fail safes that you don’t get the extremes of probabilities?
1 Like
Of course it CAN be. Anything CAN be. But can you argue, with a straight face, that if you roll a 6-sided die, six times, you will roll all six numbers? Because each number has a 1 in 6 chance?
I’m not saying that the rng isn’t broken. I haven’t coded anything even remotely complicated in like 20 years. Back then all rng were broken because random couldn’t ever be really random. I honestly have no idea if that little wrinkle ever got ironed out, or how.
My point was just that expecting random to be consistent, is expecting random to not be random. ![]()
This is very superficial and casual point of view. Random is actually very consistent by definition, probably one of the most consistent things in the universe. If random stops becoming consistent, we either moved to a different universe or random is no actual random at all. ![]()
I agree to a point. Streaks in battles are a relatively small pool and while they can be annoying if you are on the bad end… sometimes you are on the good end. I’ve never read a single thread complaining about how their 20% card fired 10 times in a row. ![]()
![]() . It’s only an issue when the AI draws the long straw. So… annoying, but only as annoying as when my husband would always roll Yahtzee back in those days.
. It’s only an issue when the AI draws the long straw. So… annoying, but only as annoying as when my husband would always roll Yahtzee back in those days.
To your point, though… on things like spending keys, it becomes a bigger deal. A painwall there would be nifty. Mainly because most players aren’t going to bail over a couple of lost battles, but I can see people quitting over always losing on the key draws.
This week alone…
How many adventure board tasks have been exactly the same on the same day…or been the same with different rarity?
Btw… My Irongut has now killed 3 troops on at least 5 casts in just the past 12 hours. I’m on delve level 310… Just started using him with Thief on 240.
But everything is fine with the code ladies and gents.

You’ve made better arguments than this in the past (see your own post cited below).
Salty is running circles around this thread because she can easily win a very simple logical argument against a flawed assertion.
She could very easily come out and say something like they ran 10 distinct runs of 10,000 simulated d20 dice rolls, checking to ensure that the result was an integer between 1 and 20. Not once did a simulated dice roll fall outside of these expected boundaries. Therefore, the RNG is not broken. Such a test would be trivially easy to run and would yield the expected results always.
But, that’s not what you’re really venting about in this thread.
What you are really trying to say here is that the RNG roll itself isn’t broken or flawed here, but rather that there’s there’s funny business going on with the result of that RNG roll.
In the form of a tabletop RPG anecdote,
Player: “I’m attacking the Treasure Gnome!”
DM: “Ok. I’ll make an attack roll.”
The d20 rolls a 16.
Player: Checks character sheet. “Great!, I only needed a 15 to hit!”
DM: “The attack misses.”
Player: “What?” /tableflip
The key piece of information missing in this anecdote is that the player was playing a Vault battle on Hard difficulty and consequentially their attack rolls had a -2 modifier to hit. This difficulty modifier was not informed to the player by the DM before the player started the encounter with the Treasure Gnome.
The problem here, IMO, is that certain game concepts, such as difficulty modifiers have become vaguer over time to players, while the devs (the DMs) are fully aware of these behind-the-scene adjustments to gameplay. After all, they have to know this information when testing and balancing content.
Once upon a time, such information was made available to players.
Spending way too much time digging in the forum history, I found a blast from the distant past on almost the same topic. Interestingly, many of the names in this thread also appear in this THREE year old post. ![]()
Scroll down a bit in that thread to see a most interesting post by Ozball, citing Sirrian, describing internal AI scoring of “lucky events”. While this information is severely dated (and likely no longer accurate), that level of detail about the inner workings of the game would probably not be provided in today’s version of the game.
From two and a half years ago, I wrote this post on almost the exact same argument that @awryan is trying to make here.
Spoiler alert: We never got one. But, one by one over time, all of the game modes replaced their player-selected difficulties (with a half-exception for Explore mode where the player can select enemy levels), with the current system that does things in the background that the player can’t directly observe.
I also remember an ancient dev Q&A where Sirrian stated that the “luck factor” (which eventually morphed into the current Difficulty system) was added to battles to make them more interesting and more arcade-like. But, after over two hours on this post alone and its research, I think I want to go enjoy my Saturday evening and not spend another 2-3 hours re-watching ancient streams to find a very specific 30-second sound bite that really isn’t going to add anything more to this post.
3 Likes
You failed to even understand my argument.
RNG streakiness is happening too often.
Any issues I’ve had prior with RNG in battles have been about something completely different.
Salty seemed to have the same misunderstanding. It’s almost as if, if anyone mentions RNG… They assume the complaint is exclusive to battles. When really RNG effects like 70% of GoW as a whole.
Big picture folks. To keep us away from the tunnel vision of RNG in battles. We can easily leave it out. And I can still easily argue that the RNG is streaking at far above the expected rate. Others can argue that it’s perfectly fine because they either aren’t paying attention, don’t care or are literally incapable of agreeing with me. Or… I’m wrong.
But again… considering the amount of things that have broken in Gems of War over the years. Pet Gnomes in the arena magically vanishing with zero explanation
…not withstanding. I feel like anything is possible…to assume otherwise would be a bit foolish.
…OR you just haven’t provided convincing enough proof that you’re right.
If you gave a list of all your Guilds’ LTs to @akots, after a week or two s/he could tell you what the confidence interval of any streaks present is/are. But no data’s been provided — only assertions based on anecdotal experience. That doesn’t mean there’s anything wrong with that, or that you’re wrong at all. It just means no one else can verify the veracity of your claims, and the devs will just gleefully reply you’re the mistaken one because you’ve not done anything to force them to admit fault of any kind.
Until data is collected à la a post by @Mithran, the devs don’t have egg on their faces, so no need to clean ![]()
1 Like
What good will that do??
This isn’t a trial. Lol
Even though I can see how it can be mistaken to read like that.
I could take screen shots for weeks… And y’all could agree with me… Like y’all all do about pet gnomes not being in the arena. And it still wouldn’t matter.
So at the risk of being flagged. Why the flying fuck should I bother compiling data for peer review? Just to have it be ignored by the developers of the game even if peers agree with me?
No where in the OP does it ask for support of other forum members. It clearly states that I, myself, think there’s an issue with RNG streaking too much, do with that info what you will. ![]()
But here you go… (Just because I took them for something else and had them on hand.)
Here are 20 LT all in order. Out of 252 completed that week.



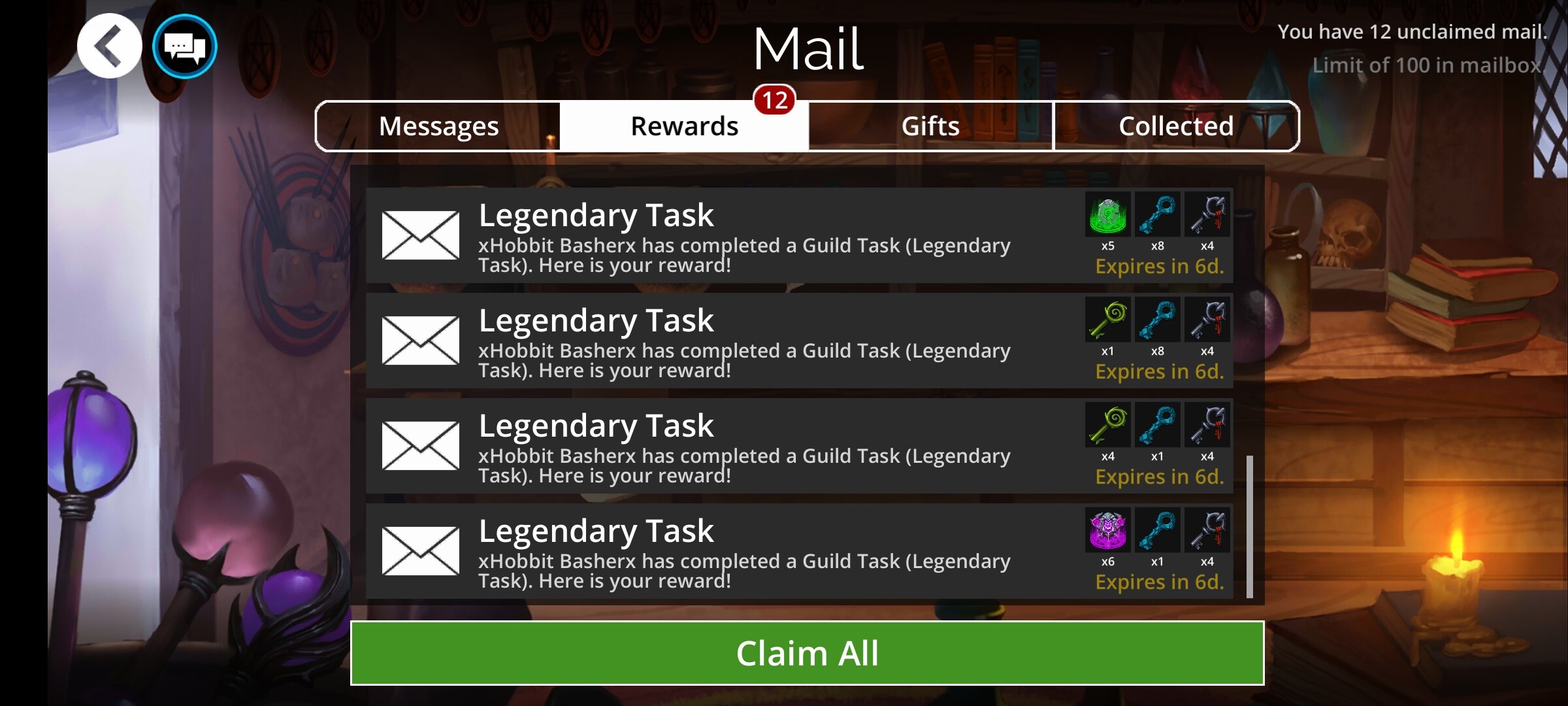

And if it was only happening with LT then I’d have to be dismissed by the “RNG streaks…it happens excuse”. But it’s not just happening there. It’s just not people.
17/20 LT = 4 Glory Keys exactly
You data lovers are welcome to compile the rest.
I didn’t isolate these LT based on the rewards. I saw the streaks and only took the SS in hopes of adjusting the way we donated in hopes of avoiding them.
But even if the member waited minutes in between donating gold or not waiting at all. It had no effect on the outcome. Even going as far as waiting 5 minutes in between donations.
I bet the devs will give a shit when we get like 10 Mythic LT back to back because of it…bet. ![]()
Lol… Then they’ll call it “an exploit” and find a way to screw us out of an issue I started reporting a while ago with it was a tiny seed the code started to break soley with LT.
I wish it was only as bad as it was when looking back.
2 Likes
There might be a reasonable way to check this, just need to come up with a clever idea. I would still prefer to do it inside the battles, it is simply easier to collect the data that way. Moreover, the data will be more reliable since it is possible to control the sequence of events, which cannot be controlled if using server pRNG. I’m sure some means will surface eventually. Also, the best way depends on the evaluation method, and methods to evaluate streakiness directly are not that easy.
I don’t think legendary tasks are a good option. They might come in conditional preset variants and may thus be nonrandom by definition. So, unless the developers provide clear specific drop chances for these, and for everything else as they should for compliance with Google Play store eventually, there is no point.
2 Likes
My bad for suggesting LTs, then. I thought that’d be a decent data-set, as I know they do dozens and probably kept track anyway (whereas I don’t think even the most hardcore-of-hardcore players keep track of individual battles in order to track, say, Agile trigger rates). But still — the reason to keep track of anything would be to get the community complaining enough to get a positive change, once irrefutable evidence pointed out we were being exploited/misled, like we did for chaos portal and troop drops in the past ![]()
Btdubs — I still haven’t found a pet gnome in Arena, and I wager I play the mode more than most. I’ll continue searching for you and the community at-large — For the Horde
I am by no means an apologist for the dev team, and think it fully possible that ninja-nerfs happen whether by miscommunication or design. It’s happened in the past, so I’ve no doubt mistakes are present and will be ongoing, whether honest or not. I’m resigned to this fact at this point, for at least as long as I continue to play.
And as far as not asking for discussion — this is the forum. If one doesn’t want input from the peanut gallery, one is better served writing PMs ![]()
1 Like
Maybe several thousand Gold Chests are a suitable place to look, since we have the official drop rates and top players could easily open large amounts? Keeping track of the data may be a tedious job though…
A 1-hour video of nonstop training battles Vs e.g. Bandits to test Agile may be less work, and any faulty RNG should be hopefully noticeable there too…
![]()
![]()
I am currently thinking about reliable ways to test conditional random. For example, agile trait is a simple example of two conditions: IF (a card takes damage from skulls/D-skulls) AND IF (agile roll is +) THEN (card takes no damage). A more complex conditional random is revival (Infernal King, Dragon Soul, etc.) or any (on death event). It will look something like that: IF (a card takes damage) AND IF (the card is eliminated) AND IF (the trait is active) AND IF (trigger roll is +) THEN (card is revived or whatever else happens). What is expected is that agile and on-death rolls are random and independent with corresponding streaks. However, since these rolls are conditioned, it might not necessarily be the case.
Chests come from the server, so this is a complete black box. Moreover, having very large dataset does not help when trying to detect streaks, it has to be optimal sequential dataset. Due to huge number of variables (need to track each card drop), this is simply not practical to do manually. Also, if you open them in bulk, you really don’t know the sequence, it has to be 1 at a time, unfortunately.
2 Likes
Streaks with my own personal offers

How many glory tasks have we gotten this week alone?

Or this month?
(I don’t have the data)
But this thread could just be a streak spam and it wouldn’t matter. They’ll look… Or they won’t look. ![]()
I think, both of these come from the server in a sort of basket. So, not really suitable for any kind of testing and really hard to acquire sufficient sample size. Same for adventures, which definitely come in a basket tied together, may be even predefined as “reasonable” to avoid random adventure with 3 deeds, for example. ![]() That would be a nice one though.
That would be a nice one though.
I’m afraid that if we really manage to expose something, it will simply lead to a simple kick of GoW from Google Play Store, which will be very unfortunate. Nobody really wants this. So, we should try to be constructive and convincing and give an ample room for developers to respond.
I’m again warning that things like these are no trivial matters. We cannot directly “catch” the server/client output and have to rely on indirect evaluation. Regulator tool, including those that are used by NIST-certified testing algorithms, have access to the raw output that is used for gambling compliance tests. So, the only way to check it out is pick something more or less simple that can be relatively easily modeled and compare with actual random type of input for the model.
In theory, it looks like this:
A. Output of game.
B. Output of model generated using random input.
Compared A and B to see if there are any differences in distribution.
Alternatively, it is possible to take some output of the game that is expected to be random and independent based on in-game description and some (limited mind you) common sense, and simply directly test randomness and independence, which is essentially based on streaks which are essentially the same thing as so-called runs. The distribution of runs for a sequence of random and independent values is a known function. So, comparison of actual runs with theoretically known runs can easily detect values that are not independent and random, if there are significant differences of course.
Keep in mind that too small sample size will not produce sufficient power of comparison and too large sample size will be random anyhow due to the law of large numbers and central limit theorem. I don’t want to go into details here since anybody who is actually interested can google it or simply read the wiki.
2 Likes

Lets make a great example of how RNG works when it comes to %, a top notch example:
-
Everyone that have been in this game for some time know the troop Queen Beetrix, right?
-
Have you ever tried to get a Queen Beetrix team going? Its exceptionally hard, and it should be as its just 40 % chance of getting an extra turn.
-
Then ask yourselves, when you are up against CPUs Queen Beetrix team 9 out of 10 times IF CPU get the her to the point ready to cast and cast her - CPU get extra turn and extra turn time after time until you are dead meat. So this proves that its a lot higher % for CPUs Beetrix than the 40 %.
Only 1 example is needed to prove it all. The RNG is not the same for CPU and Human, its differently. Every player that have been around in this game for years knows this.
Does it works as intended, yes indeed.
And here Tabu Goodwill, CPU therfor is more likely to get the streakiness cuz the chances (%) is higher for it to happen. Lets not lie to ourselves. Lets man up and face the truth.
2 Likes
and @ButtStallion feel free to explain how the CPUs 20 % Agile trait works versus Humans…